

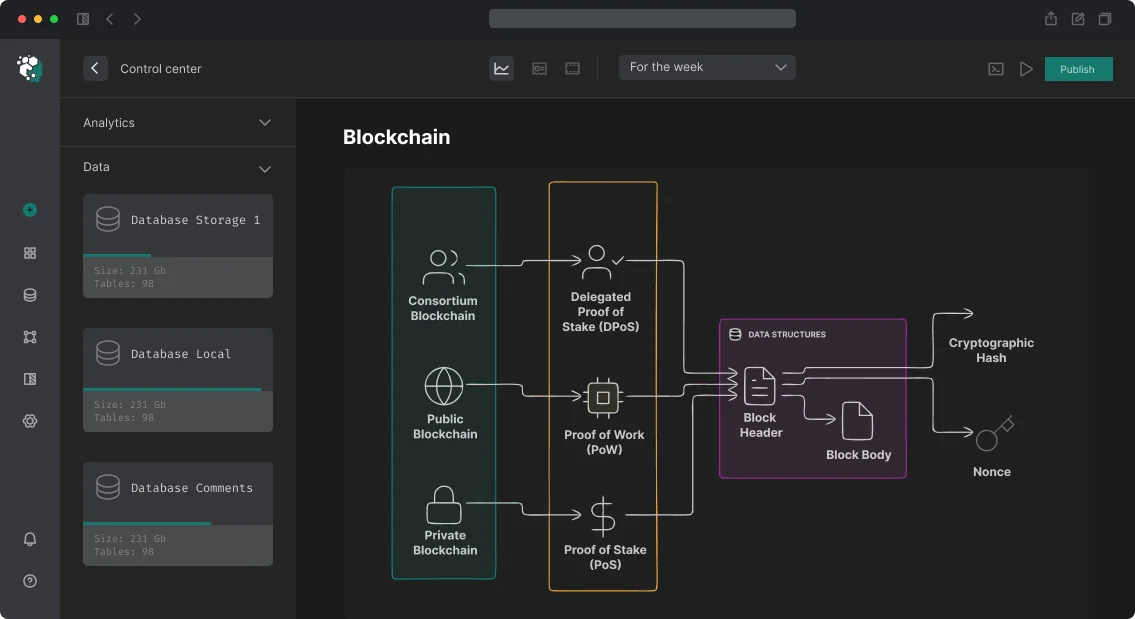
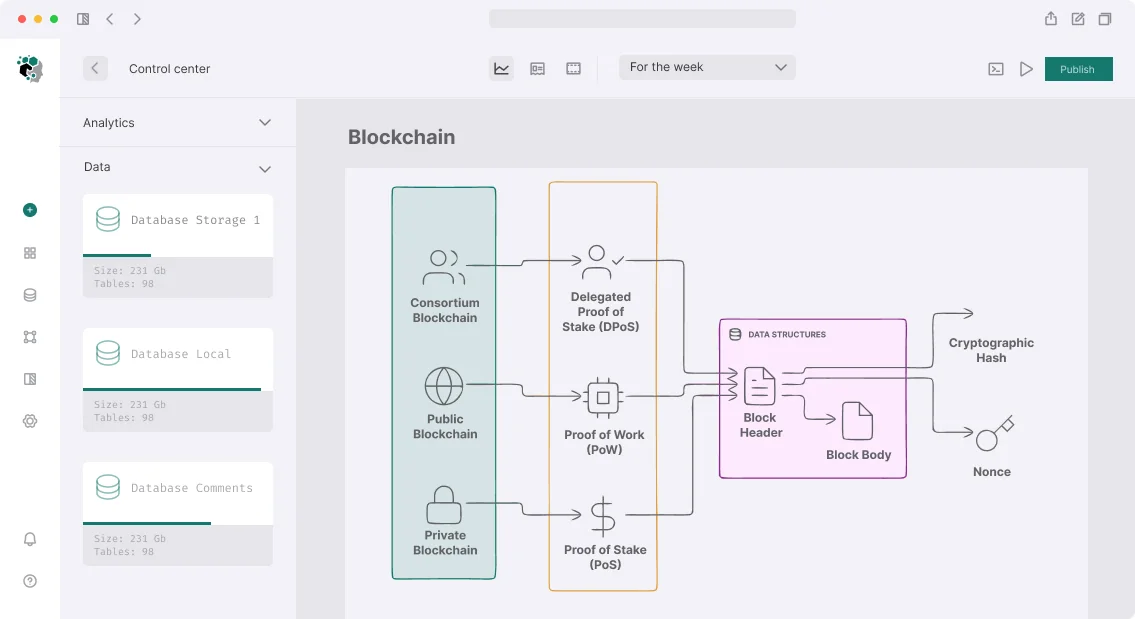





Developing a Custom Blockchain Indexer
The Graph solves 80% of indexing tasks. The remaining 20% is when you need complex data aggregation on-the-fly, cross-chain indexing with state merging, access to data that never made it to events (storage slots, trace calls), subsecond latency, or full infrastructure control without vendor lock-in. This is when a custom indexer is built.
Architectural Decisions Before Starting
Before writing code, you need to answer three questions:
Data source. Logs/events are the cheapest way, but only what the contract explicitly emits. Traces (internal transactions) require an archive node with trace_ namespace or Erigon with --tracing. Storage proofs for state that was never emitted as events. The choice of source determines node requirements and parsing complexity.
Consistency model. Do you need exact consistency (reorg handling) or is eventual consistency enough? For financial data, reorganizations are not rare. On Ethereum mainnet, reorgs of depth 1-2 blocks happen several times a day. Finality depth for safe confirmation is 12-15 blocks on PoS Ethereum.
Latency requirements. Real-time (< 1 sec from block) requires WebSocket + streaming. Analytics (minutes/hours) is sufficient with batch processing.
System Components
Data Ingestion Layer
Three patterns for getting data from a node:
JSON-RPC polling — simplest variant. eth_getLogs with filter by address and topics, eth_getBlockByNumber. Latency = polling interval (usually 500ms-2sec). Problem: at high RPS, the node starts to throttle.
WebSocket subscriptions — eth_subscribe("newHeads") and eth_subscribe("logs", filter). Latency close to block time. Problem: on reconnect you can miss blocks, you need catch-up logic.
Direct P2P — connecting to Ethereum P2P network via devp2p/libp2p, getting blocks directly without RPC. Minimal latency, but high implementation complexity. Practical only if the indexer is physically close to validators.
For production I recommend WebSocket + catch-up mechanism:
async def subscribe_blocks(ws_url: str, from_block: int):
# First catch up to current block
current = await rpc.eth_block_number()
for block_num in range(from_block, current):
block = await rpc.eth_get_block_by_number(block_num)
await process_block(block)
# Then subscribe to new ones
async with websockets.connect(ws_url) as ws:
await ws.send(json.dumps({
"method": "eth_subscribe",
"params": ["newHeads"]
}))
async for message in ws:
head = json.loads(message)
await process_new_head(head)
ABI Decoding
Raw log is an array of topics (bytes32) and data (bytes). Decoding via ABI:
import { decodeEventLog, parseAbi } from 'viem';
const abi = parseAbi([
'event Transfer(address indexed from, address indexed to, uint256 value)'
]);
const decoded = decodeEventLog({
abi,
data: log.data,
topics: log.topics,
});
// decoded.args.from, decoded.args.to, decoded.args.value
Indexed parameters are encoded in topics (topic[0] = keccak256 of signature, topic[1..3] = indexed args). Non-indexed are in data via ABI encoding.
Decoding problems:
- Anonymous events — no topic[0], matching only by address
-
Proxy contracts — ABI of implementation, not proxy. Need to resolve via
implementation()slot (EIP-1967: slot0x360894...) - Upgrade events — after upgrade ABI changes, need versioning
Reorg Handling
This is the most unpleasant part of a custom indexer. Reorg means blocks you've already processed are no longer canonical.
Pattern: each record in the database contains block_hash and block_number. When processing a new block, we check the parent:
-- Reorg detection
SELECT block_hash, block_number
FROM processed_blocks
WHERE block_number = $1 AND block_hash != $2;
-- If there are rows — this is a reorg
When a reorg is detected:
- Find the divergence point (common ancestor)
- Rollback all records from divergence point to current block (
DELETE WHERE block_number >= fork_point) - Reprocess canonical blocks
For this you need atomic block processing — all changes from one block are applied in a single database transaction with block_hash as identifier.
BEGIN;
DELETE FROM events WHERE block_hash = $orphaned_hash;
DELETE FROM processed_blocks WHERE block_hash = $orphaned_hash;
-- insert canonical data
INSERT INTO processed_blocks (block_number, block_hash, ...) VALUES (...);
INSERT INTO events (...) VALUES (...);
COMMIT;
Storage Layer
Database choice is determined by query patterns:
| Scenario | Technology | Reason |
|---|---|---|
| Time-series data (prices, volumes) | TimescaleDB | Hypertables, auto-compression, continuous aggregates |
| Graph queries (account relationships) | PostgreSQL + ltree or Neo4j | Recursive queries or graph-native DB |
| Full-text search over NFT metadata | PostgreSQL + GIN index | jsonb + GIN indexes for JSON fields |
| OLAP analytics | ClickHouse | Columnar storage, vectorized execution |
| Current state cache | Redis | Hash structures for balances, pub/sub for streaming |
For most DeFi indexers: PostgreSQL for core data + Redis for hot cache.
API Layer
GraphQL via Hasura (auto-generation from PostgreSQL schema) or manually via Apollo Server. REST for simple cases.
Critical optimization: DataLoader for batching queries. If GraphQL query asks for transfers { from { balance } } — without DataLoader you get N+1 queries to DB. DataLoader groups queries into a single event loop tick.
Subscriptions for real-time data: PostgreSQL LISTEN/NOTIFY → WebSocket → GraphQL subscription.
Performance and Scaling
Bottlenecks in order of frequency:
Parallel block processing. Blocks are independent if there's no cross-block state (usually there isn't). Worker pool of N threads, each processing its own block range. Caution: order of writes to DB must be deterministic.
Batch insert. Don't INSERT each event separately. PostgreSQL COPY or INSERT ... VALUES (…),(…),(…) — difference of 10-50x in throughput.
# Bad: N separate INSERTs
for event in events:
await db.execute("INSERT INTO events VALUES ($1, $2, ...)", event)
# Good: single batch INSERT
await db.executemany(
"INSERT INTO events VALUES ($1, $2, ...)",
[(e.block, e.tx_hash, ...) for e in events]
)
Indexes vs insert speed. Each index slows down INSERT. For historical sync: create table without indexes, load data, then CREATE INDEX CONCURRENTLY. 3-10x speedup compared to indexes during loading.
Technology Stack
| Component | Options |
|---|---|
| Ingestion language | TypeScript/Node.js (viem/ethers ecosystem), Python (web3.py), Rust (ethers-rs/alloy) |
| Queue | Redis Streams, Apache Kafka (> 10k events/sec) |
| Database | PostgreSQL 16 + TimescaleDB |
| API | Hasura (quick start) or custom GraphQL |
| Monitoring | Prometheus + Grafana, alerting by lag metric |
| Deploy | Docker Compose (dev), Kubernetes (prod) |
Rust (alloy crate) gives the best performance for high-load indexers: ABI parsing, block deserialization, bytes operations — all 5-20x faster than Node.js.
Monitoring and Operations
Key metrics:
-
Indexer lag — difference between
latest_blockin DB andeth_blockNumber. Alert if > 10 blocks. - Reorg count — number of reorgs per period. Sudden increase = problems with node or RPC.
- Events per block — anomalies indicate unusual activity or parsing bugs.
- DB write latency — degradation means you need vacuum, bloat, or sharding.
# Example Prometheus alert
- alert: IndexerLagHigh
expr: eth_latest_block - indexer_processed_block > 50
for: 2m
annotations:
summary: "Indexer is falling behind by {{ $value }} blocks"
Workflow
Design (3-5 days). Determining data sources, DB schema, real-time requirements. Choosing between custom development and extending existing solutions (Ponder, Substreams).
Core development (5-10 days). Ingestion + decoding + reorg handling + storage. This is the critical path, tested on historical data.
API and integrations (3-5 days). GraphQL/REST schema, subscriptions, documentation.
Load testing and optimization (2-3 days). Sync from genesis, API load testing, connection pool tuning, indexes.
Deploy and monitoring (1-2 days). Docker Compose / Kubernetes, alert setup, runbook for on-call.
Total: 1-2 weeks for single-protocol indexer on one network. Multi-chain with aggregation closer to 3-4 weeks.