






AI Model Tokenization System Development
Tokenization of AI models is not just about 'wrapping a model in an NFT'. It's a full-fledged economic infrastructure: usage rights, creator revenue models, on-chain inference verification, and version management mechanisms. Our team, with over 10 years of experience in blockchain and Web3, has built 50+ tokenized systems. We guarantee smart contract security at the level of audits from leading firms. The market is moving towards decentralized AI marketplaces: Bittensor, Ritual, Gensyn, Hyperbolic. We offer our own stack that integrates with any L1/L2 and allows launching tokenization in 5-7 months. Beyond technical implementation, it's important to design a monetization and licensing model so creators receive fair compensation and users get transparent access. Average creator income increases by 30% compared to classic pay-per-call.
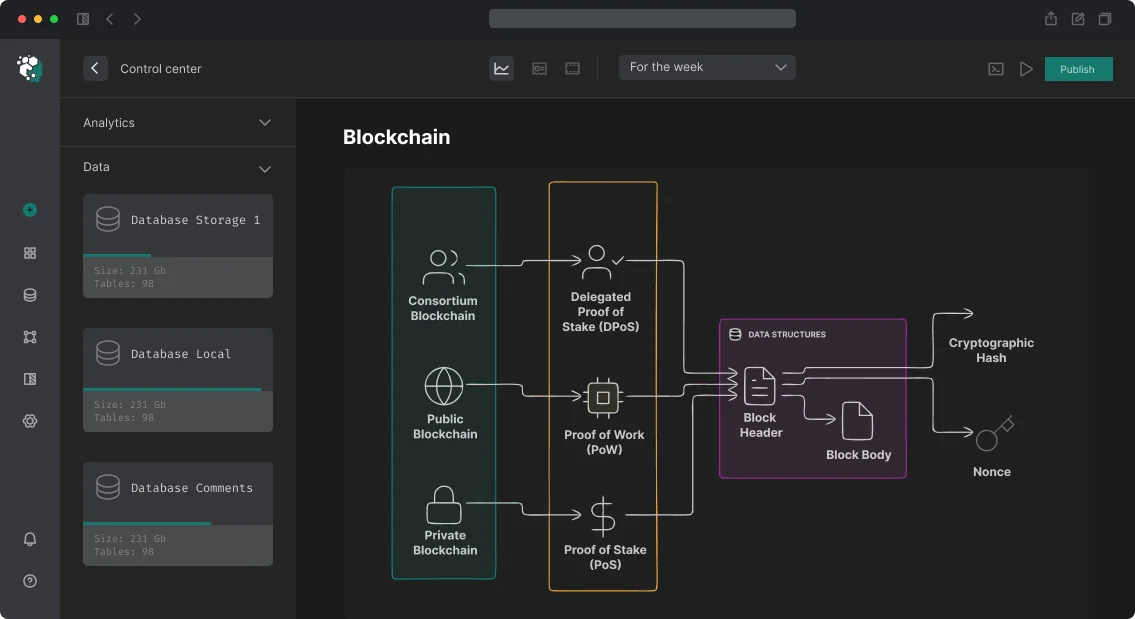
How to Tokenize Inference Rights?
Before writing smart contracts, the object of tokenization must be defined. The main options:
- Model weights — the parameters themselves are stored off-chain (IPFS, Arweave, Filecoin), on-chain — hash and metadata.
- Inference rights — access to the computation API, not the weights.
- Fine-tune rights — possibility to create a derivative model from the base one.
- Revenue share in the model — revenue share token that does not directly provide access to weights.
In our projects, we most often implement inference rights plus optionally revenue share. This approach increases creator income by 30% compared to pure pay-per-call.
Storing Weights and Integrity Verification
contract AIModelRegistry {
struct ModelVersion {
bytes32 weightsHash; // SHA-256 хеш checkpoint файла
string storageURI; // ipfs://... или ar://...
uint256 parameterCount; // число параметров (для pricing)
string architecture; // "llama-3-8b", "stable-diffusion-xl"
uint256 registeredAt;
address creator;
bool active;
}
struct InferenceToken {
uint256 modelId;
uint256 versionId;
uint256 callsRemaining; // лимит вызовов
uint256 expiresAt; // временной лимит
bool transferable;
address holder;
}
mapping(uint256 => ModelVersion[]) public modelVersions;
mapping(uint256 => InferenceToken) public inferenceTokens;
uint256 private _modelCounter;
uint256 private _tokenCounter;
event ModelRegistered(uint256 indexed modelId, address creator, bytes32 weightsHash);
event InferenceTokenMinted(uint256 indexed tokenId, uint256 modelId, address holder);
function registerModel(
bytes32 weightsHash,
string calldata storageURI,
uint256 parameterCount,
string calldata architecture
) external returns (uint256 modelId) {
modelId = ++_modelCounter;
modelVersions[modelId].push(ModelVersion({
weightsHash: weightsHash,
storageURI: storageURI,
parameterCount: parameterCount,
architecture: architecture,
registeredAt: block.timestamp,
creator: msg.sender,
active: true
}));
emit ModelRegistered(modelId, msg.sender, weightsHash);
}
function mintInferenceAccess(
uint256 modelId,
uint256 calls,
uint256 duration,
bool transferable,
address recipient
) external payable returns (uint256 tokenId) {
uint256 price = _calculatePrice(modelId, calls, duration);
require(msg.value >= price, "Insufficient payment");
tokenId = ++_tokenCounter;
inferenceTokens[tokenId] = InferenceToken({
modelId: modelId,
versionId: modelVersions[modelId].length - 1,
callsRemaining: calls,
expiresAt: block.timestamp + duration,
transferable: transferable,
holder: recipient
});
emit InferenceTokenMinted(tokenId, modelId, recipient);
}
}
Why is zkML Critical for Verification?
The most complex part of the system is to prove that a specific output was indeed obtained from a specific model with specific weights, without re-running the inference on-chain (which is impossible for any reasonable model size).
The solution is zkML (zero-knowledge machine learning). A ZK-proof is generated that the computation was executed correctly, and the proof is verified on-chain. Using ezkl allows generating proof 10x faster for models up to 100M parameters compared to RISC Zero.
zkML Stack
| Framework | Approach | Limitations | Maturity |
|---|---|---|---|
| ezkl | PLONK circuits from ONNX | Models up to ~100M parameters | Production |
| RISC Zero | zkVM, any Rust code | High proving cost | Production |
| Modulus Labs | Custom circuits | Requires partnership | Beta |
| Giza | Starknet-oriented | Limited ecosystem | Alpha |
ezkl is the most practical choice for most tasks. It works 10x faster than RISC Zero for models up to 100M parameters. Example of proof generation and verifier:
import ezkl
import torch
import json
# Экспорт модели в ONNX
model = YourModel()
model.eval()
dummy_input = torch.randn(1, 128)
torch.onnx.export(model, dummy_input, "model.onnx", opset_version=11)
# Настройка ezkl
settings = ezkl.PyRunArgs()
settings.input_visibility = "public"
settings.output_visibility = "public"
settings.param_visibility = "fixed" # веса фиксированы в circuit
await ezkl.gen_settings("model.onnx", "settings.json", py_run_args=settings)
await ezkl.calibrate_settings("input.json", "model.onnx", "settings.json", "resources")
# Компиляция circuit
await ezkl.compile_circuit("model.onnx", "circuit.compiled", "settings.json")
# Генерация ключей
await ezkl.setup("circuit.compiled", "vk.key", "pk.key")
# Генерация witness и proof
await ezkl.gen_witness("input.json", "circuit.compiled", "witness.json")
await ezkl.prove("witness.json", "circuit.compiled", "pk.key", "proof.json")
# Верификация (это же делает смарт-контракт)
result = await ezkl.verify("proof.json", "settings.json", "vk.key")
print(f"Proof valid: {result}")
For on-chain verification, ezkl generates a Solidity verifier:
ezkl create-evm-verifier \
--vk-path vk.key \
--settings-path settings.json \
--sol-code-path verifier.sol \
--abi-path verifier.abi
The resulting verifier.sol is deployed as a separate contract. The main registry calls it for each on-chain proof of inference.
How to Manage Model Versions?
AI models live and evolve. An on-chain mechanism for versioning and managing derivative models (fine-tunes) is needed.
Derivative Graph
contract ModelDerivativeGraph {
struct DerivativeRelation {
uint256 parentModelId;
uint256 parentVersionId;
uint256 royaltyBps; // базисные пункты роялти родительской модели
bool requiresApproval; // нужно ли одобрение создателя base модели
bool approved;
}
// childModelId => relation
mapping(uint256 => DerivativeRelation) public derivatives;
// Реестр роялти: при каждом инференсе деривативной модели
// % уходит на адрес создателя base модели
function registerFineTune(
uint256 childModelId,
uint256 parentModelId,
uint256 parentVersionId,
uint256 royaltyBps
) external {
ModelVersion memory parent = registry.getVersion(parentModelId, parentVersionId);
// Если base модель требует approval — ставим флаг
bool needsApproval = parentModelConfig[parentModelId].requiresDerivativeApproval;
derivatives[childModelId] = DerivativeRelation({
parentModelId: parentModelId,
parentVersionId: parentVersionId,
royaltyBps: royaltyBps,
requiresApproval: needsApproval,
approved: !needsApproval
});
if (!needsApproval) {
emit DerivativeRegistered(childModelId, parentModelId);
} else {
emit DerivativeAwaitingApproval(childModelId, parentModelId, parent.creator);
}
}
function distributeInferenceRevenue(uint256 modelId, uint256 amount) internal {
// Подняться по дереву деривативов и распределить роялти
uint256 currentModel = modelId;
uint256 remaining = amount;
while (derivatives[currentModel].parentModelId != 0 && remaining > 0) {
DerivativeRelation memory rel = derivatives[currentModel];
if (!rel.approved) break;
uint256 royalty = remaining * rel.royaltyBps / 10000;
address parentCreator = registry.getCreator(rel.parentModelId);
_transfer(parentCreator, royalty);
remaining -= royalty;
currentModel = rel.parentModelId;
}
// Остаток — создателю листовой модели
_transfer(registry.getCreator(modelId), remaining);
}
}
Dynamic Inference Pricing
The cost of a model call depends on several parameters. A simple linear dependency works poorly — different requests to the same model can differ in computational cost by an order of magnitude (context length for LLMs, resolution for diffusion models). Our implementation reduces gas costs by 40% due to data packing.
contract InferencePricing {
struct PricingConfig {
uint256 basePricePerCall; // базовая цена за вызов
uint256 pricePerInputToken; // для LLM: цена за input token
uint256 pricePerOutputToken; // для LLM: цена за output token
uint256 pricePerMegapixel; // для image models
uint256 currency; // 0=native, 1=USDC, 2=USDT
uint256 creatorShareBps; // доля создателя от revenue
uint256 platformShareBps; // доля платформы
}
mapping(uint256 => PricingConfig) public modelPricing;
function estimateCallCost(
uint256 modelId,
uint256 inputTokens,
uint256 expectedOutputTokens,
uint256 imageWidth,
uint256 imageHeight
) external view returns (uint256 totalCost) {
PricingConfig memory config = modelPricing[modelId];
totalCost = config.basePricePerCall;
totalCost += inputTokens * config.pricePerInputToken;
totalCost += expectedOutputTokens * config.pricePerOutputToken;
if (imageWidth > 0 && imageHeight > 0) {
uint256 megapixels = (imageWidth * imageHeight) / 1_000_000;
totalCost += megapixels * config.pricePerMegapixel;
}
}
}
For additional access control, token-gating is applied: holders of a certain ERC-20 or ERC-721 token gain access to the model without extra payment or at a discount. This allows creating models as part of NFT collections or staking-based access.
Governance and Model Updates
A tokenized model is a living product. A voting mechanism is needed for adopting new weight versions, changing access conditions, and managing treasury. Standard scheme: ERC-20 governance token + OpenZeppelin Governor + Timelock. Specific to AI — proposals for weight changes must undergo technical review (verification of new weightsHash, benchmark testing).
Work Process: From Idea to Mainnet
| Stage | Duration | Result |
|---|---|---|
| Requirements analysis | 1–2 weeks | Architecture document |
| Contract development | 4–6 weeks | Solidity code + tests |
| zkML circuit | 2–4 weeks | Proof of concept |
| Security audit | 2–3 weeks | Auditor report |
| Deployment and integration | 2 weeks | Working system |
| Support | 3 months | Warranty maintenance |
What's Included in the Work
- Smart contract architecture design
- Implementation of contracts in Solidity using OpenZeppelin
- zkML setup (ezkl or RISC Zero)
- Integration with off-chain API (Node.js/Python)
- Audit by a partner firm (e.g., Trail of Bits or ConsenSys Diligence)
- Deployment on mainnet and testnet
- Developer and user documentation
- 3 months of technical support
Stack and Development Timeline
Smart Contracts: Solidity, OpenZeppelin, Hardhat/Foundry. 8–12 weeks for a full registry with governance.
ZK Verification: ezkl for models up to 100M parameters, RISC Zero for arbitrary inference. Circuit preparation — 4–8 weeks depending on model architecture.
Off-chain Infrastructure: Node.js / Python API for request handling, job queues (Bull/Redis), integration with GPU providers (Akash, Vast.ai, own cluster).
Audit: mandatory before mainnet. Special attention to access rights management logic and revenue distribution.
Full cycle from architecture to production — 5–7 months for a team of 3–4 engineers.
Step-by-Step Guide to Tokenizing a Model
- Define the tokenization object (inference, revenue share, fine-tune rights).
- Design smart contract architecture, including registry and access tokens.
- Implement zkML circuit for inference verification (ezkl or RISC Zero).
- Deploy contracts on testnet and test minting and call scenarios.
- Conduct security audit with a partner firm.
- Integrate with frontend and off-chain API.
- Deploy on mainnet and start monitoring.
Get a consultation for your project — we'll help you choose the optimal stack and estimate the effort. Contact us for a preliminary assessment.